
Portfolio
Step Into My Creative Lab
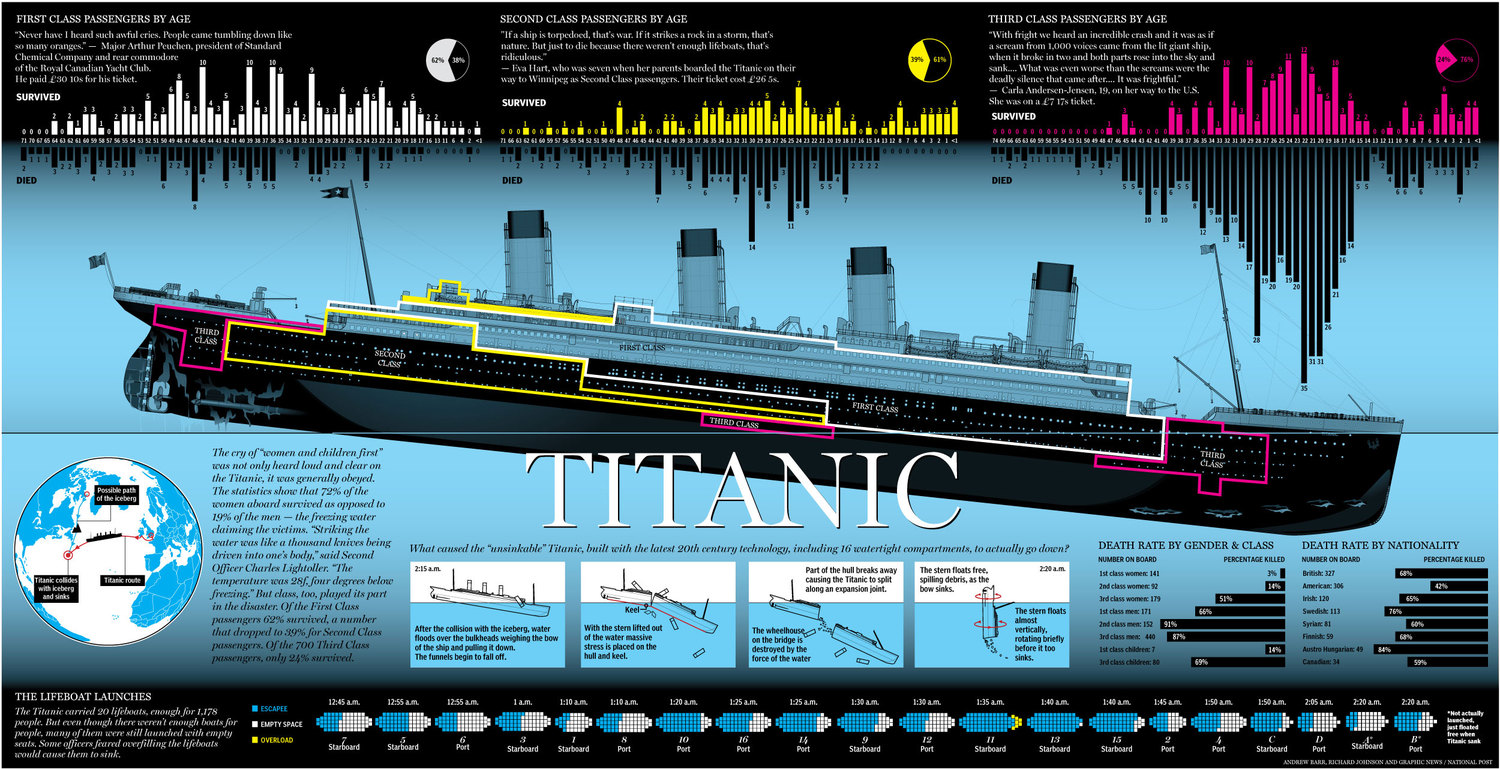
Titanic: Machine Learning from Disaster
A project focused on predicting survival rates from the Titanic disaster based on passenger data. In this project, machine learning algorithms such as logistic regression, decision trees, and random forests were used to build models and predict which passengers survived and which did not.
Key skills: Data Cleaning, Feature Engineering, Classification, Model Evaluation, Hyperparameter Tuning, and Data Visualization.

ProText Analyzer
ProText Analyzer is a comprehensive tool for text analysis. It extracts textual data from URLs, performs sentiment analysis using TextBlob, and calculates readability metrics like Fog Index and Average Sentence Length. The project also handles syllable counting with Syllapy and advanced text processing using spaCy. It provides a clean and structured output ready for review.
Cognifyz Data Science Projects
Explore a variety of data science projects focusing on data exploration, machine learning, geospatial analysis, restaurant dataset insights, and predictive modeling.

House Price Prediction
Predict house prices based on features such as square footage, location, number of rooms, and more using regression models, feature engineering, and model evaluation techniques like MSE and RMSE.

Loan Approval Prediction
In this advanced machine learning project, we focus on predicting whether a loan application will be approved or rejected based on an applicant’s financial profile. By leveraging data such as income, credit history, loan amount, and employment status, we apply various classification algorithms to build a robust predictive model. The project involves meticulous data preprocessing, feature selection, and engineering to ensure the model's accuracy. We also evaluate the model’s performance using essential metrics like accuracy, precision, recall, and F1-score to ensure reliability in real-world banking applications. This solution can assist financial institutions in automating their decision-making processes and improving loan approval efficiency.

Airbnb Price Prediction
In this advanced machine learning project, we predict Airbnb listing prices by analyzing various features such as location, number of rooms, guest reviews, and available amenities. By employing regression models, we can estimate accurate pricing for each listing. The project involves extensive data preprocessing, including handling missing values, scaling, and encoding categorical variables. Feature engineering plays a vital role in improving the model's performance by selecting the most impactful features. We also use model evaluation techniques such as RMSE and R-squared to assess the accuracy and generalizability of the predictions, making it a comprehensive approach for real estate price prediction.
Predicting Customer Lifetime Value (CLV)
Dive into an advanced project aimed at predicting the lifetime value of customers using the Online Retail Dataset (UCI). This project applies sophisticated techniques such as Gradient Boosting, Bayesian Regression, ARIMA, and more. Key skills include advanced regression modeling, feature engineering, and survival analysis, with a focus on accurate and actionable predictions.

Image Classification using Deep Learning
An advanced project focused on building image classification models for tasks like medical diagnosis, autonomous vehicles, and plant disease detection. This project utilizes datasets such as CIFAR-10/100 and Kaggle's Diabetic Retinopathy Detection. Core techniques include Convolutional Neural Networks (CNNs), Transfer Learning, and Image Augmentation, implemented using TensorFlow, PyTorch, and Keras.

Fraud Detection
This advanced project focuses on detecting fraudulent transactions in financial datasets using Kaggle's Credit Card Fraud Detection dataset. Key techniques include handling imbalanced data with SMOTE, applying Isolation Forests for anomaly detection, and leveraging XGBoost for robust predictive modeling.

Fraud Detection in Financial Transactions
This advanced-level project focuses on building a robust fraud detection system capable of identifying fraudulent financial transactions in real-time. Using datasets such as IEEE-CIS Fraud Detection and Credit Card Fraud Detection, the project tackles challenges like highly imbalanced data distribution by employing techniques like SMOTE and ADASYN. Cutting-edge models such as Autoencoders and Isolation Forest are used for anomaly detection, while powerful ensemble techniques like XGBoost and LightGBM enhance predictive accuracy. Incorporating time-series data analysis ensures the system adapts to dynamic transaction patterns, making it highly effective for real-world financial applications.
About Me
Exploring, evolving, and uncovering new possibilities every day
I often find myself wondering: Have I changed today? Was I the same person I was when I began this journey, or did something shift along the way? Maybe, just maybe, I’ve learned something new, solved a complex problem, or discovered a hidden pattern in data that made me see the world a little differently. But if I’m not exactly the same, then the real question is, "Who am I, really?" And that’s the puzzle that keeps me going.
Life is an endless evolution, constantly growing and embracing the uncertainty that comes with each new challenge. In the world of Data Science, there’s always something new to learn, a new project to tackle, or a fresh perspective to explore. Each dataset, every machine learning model, and every problem solved doesn’t just teach me technical skills, but helps me understand more about who I am and what I’m capable of. I may not have all the answers yet, but with every step I take, I’m uncovering more of them. This journey never ends, and that’s what makes it so exciting.
Data Collection
I gather diverse data — structured, semi-structured, and unstructured — from various sources like databases, APIs, web scraping, and IoT sensors. I use powerful tools like Pandas, Requests, BeautifulSoup, and Scrapy for efficient data extraction and processing.
Data Cleaning and Preprocessing
I clean and preprocess data by handling missing values, transforming features, detecting outliers, and merging datasets. I use powerful tools like Pandas, NumPy, and Scikit-learn to make sure the data is ready for analysis.

Exploratory Data Analysis (EDA)
I perform exploratory data analysis (EDA) to uncover patterns, trends, and insights from data. By leveraging statistical summaries and visualizations, I generate actionable insights using tools like Pandas, Matplotlib, Seaborn, and Power BI.
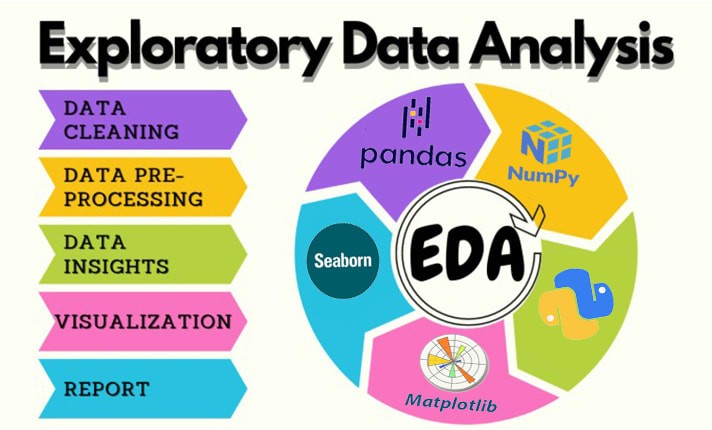
Data Analysis
I conduct comprehensive data analysis to summarize data, identify causes, forecast outcomes, and recommend actions. I use tools like Python (StatsModels, SciPy), SQL, and Excel to perform these tasks effectively.

Statistical Modeling
I build statistical models to analyze and understand data, using methods like linear regression, logistic regression, hypothesis testing, and time series analysis. My go-to tools include StatsModels and SciPy.

Machine Learning Development
supervised and unsupervised learning techniques. I focus on training, tuning, and optimizing models, making them ready for production deployment. My preferred tools include Scikit-learn, XGBoost, and LightGBM.

Deep Learning
I build deep learning models for tasks like image classification, object detection, text classification, and sentiment analysis. My preferred tools include TensorFlow, Keras, PyTorch, Hugging Face, OpenCV, and NLTK.

Data Visualization and Reporting
I design interactive dashboards and craft compelling data stories to effectively communicate insights to stakeholders. Tools: Power BI, Plotly, Dash, Matplotlib, Seaborn.
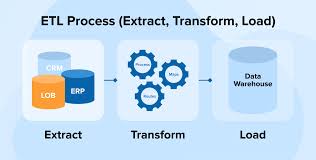
Data Pipelines and Automation
I automate data workflows by implementing ETL processes, efficiently collecting, transforming, and loading data into storage systems to empower data-driven decision-making.
Data Storage and Management
I manage and store data in relational databases using SQL-based systems like MySQL, ensuring efficient retrieval and secure storage for optimal data access.

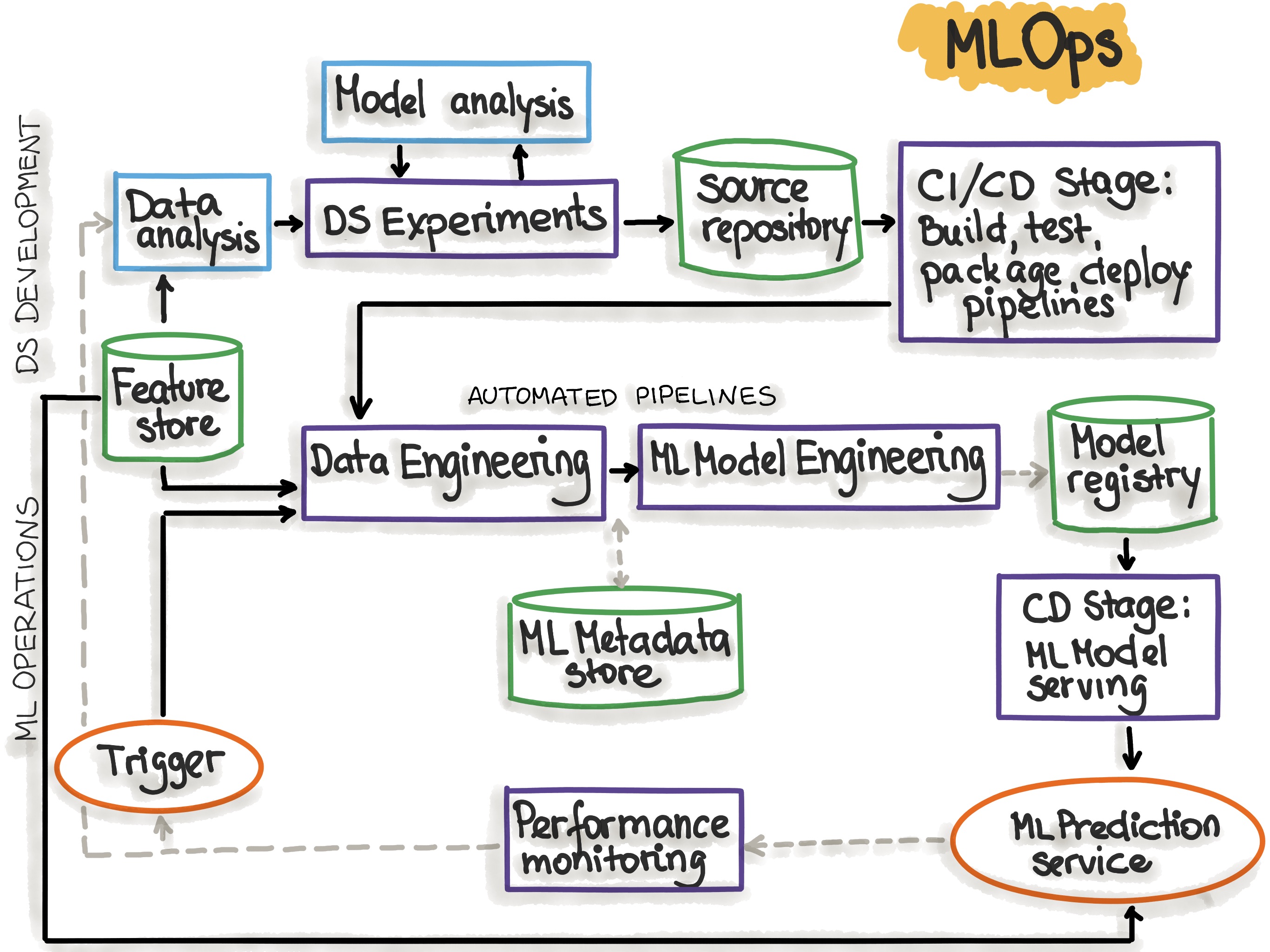
Model Deployment and MLOps
I deploy machine learning models into production, monitor their performance, and ensure scalability using containerization technologies like Docker and Kubernetes. Key tools: Flask, FastAPI, MLflow, AWS SageMaker, Docker.
Optimization and Automation
In my experience, improving model accuracy through hyperparameter tuning is crucial for optimizing performance. At the same time, automating repetitive tasks can significantly enhance overall efficiency. To achieve this, I use tools like Optuna and GridSearchCV for fine-tuning model parameters, and I implement Automation scripts to streamline workflows and save time.

Business Intelligence and Decision-Making
I focus on enabling data-driven decision-making by tracking key performance indicators (KPIs) that measure success. I leverage tools like Power BI and Excel Dashboards to create insightful visualizations and reports, helping businesses make informed decisions based on real-time data analysis.
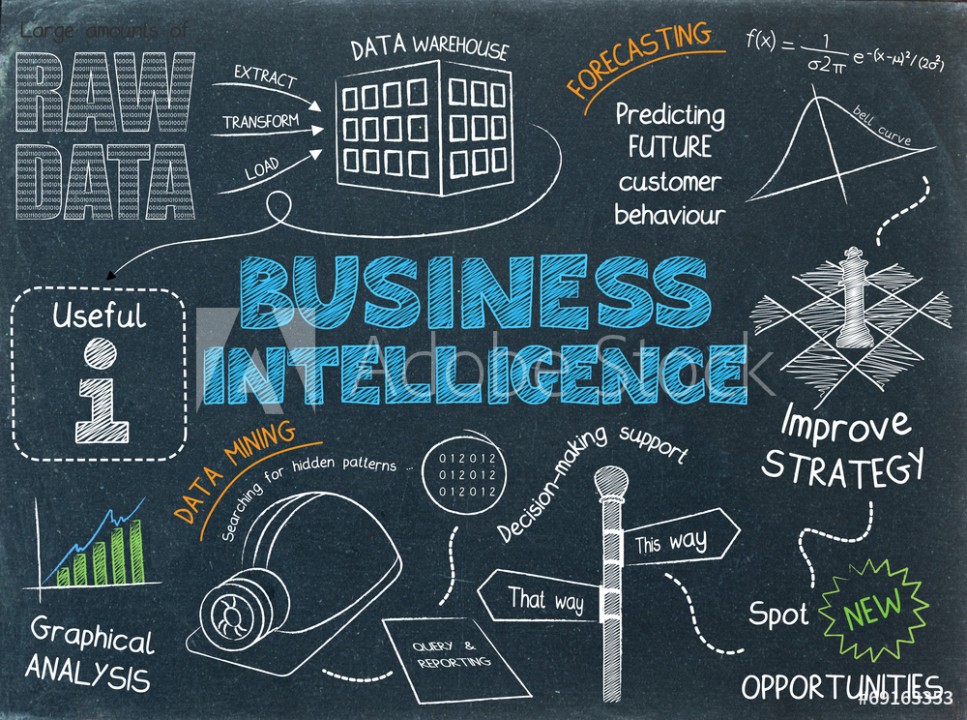
Research and Experimentation
I actively engage in research and experimentation to test different approaches and solve unique problems. This includes conducting A/B testing to validate hypotheses and using advanced tools like SciPy, NumPy, and PyExperimenter to build custom models and algorithms. Through this, I continuously innovate and refine processes for optimal outcomes.

Resume
Education and practical experience
The biggest risk is not taking any risk... In a world that's changing really quickly, the only strategy that is guaranteed to fail is not taking risks.
The person I am today is a direct result of the risks I’ve taken. Every challenge, every new project, and every step into the unknown has shaped my journey. For me, education isn’t just about gaining knowledge—it’s about pushing my limits, embracing new opportunities, and evolving with each experience. Every risk I take brings me closer to unlocking new possibilities and becoming the best version of myself.
My education
12th Grade (Science Stream)
Studied at Sarvodaya Kanya Vidyalaya, Pocket 4
Senior Secondary Level - Science Stream
Bachelor of Computer Applications (BCA) - Data Science
Studying at Amity University
Pursuing BCA with specialization in Data Science
Data Science (1-Year Hand-to-Hand Experience)
Trained at Vcare Technical Coding Institute
Practical Training in Data Science
Machine Learning & AI Training
Trained at Vcare Technical Coding Institute
Practical Training in Machine Learning and AI
My Favourite Tools & Libraries
Python
NumPy
Pandas
Matplotlib
Seaborn
Plotly
Folium
Dask
SciPy
Statsmodel
Scikit-learn
XGBoost

LightGBM

Tensorflow

Keras

PyTorch

NLTK

SpaCy
Hugging Face
Random Forest
SQL
MySQL
Power BI
Jupyter
Google Colab
Anaconda
VS Code
Git
GitHub
Dash
Testimonials
What My Close Ones Say About Me

Ruby is an extremely passionate and enthusiastic data scientist. Every day, her curiosity and drive to learn something new inspire everyone around her. She tackles problems with immense creativity and constantly explores new possibilities. Watching her grow and evolve into such an exceptional professional has been truly amazing. I'm proud to see how much she's achieved and excited for her future success!
Ruby is the backbone of our 5-member team at Vcare Technical Coding Institute. She not only manages but also excels in every data science project we take on—whether it's machine learning, AI, or computer vision. Her relentless drive to explore, learn, and solve complex problems inspires all of us. With her leadership and expertise, every project feels like an opportunity to grow. I’m truly excited for the remarkable journey ahead for Ruby!

I still remember when she started her journey with zero knowledge in Data Science, but her relentless commitment, practicing 12 hours a day, and her thirst for exploring new depths made her unstoppable. Watching her grow into a confident, skilled professional has been one of the most fulfilling experiences of my teaching career. She’s not just a student; she’s an inspiration.

Ruby is truly exceptional! From basic to advanced projects, her ability to grasp and explain even the toughest concepts is extraordinary. Every collaboration with her has been a learning experience, and her unique perspective always adds value. Not only is she an outstanding communicator, but she also manages every task with grace and efficiency, making her a standout in any team!

When I switched from full-stack development to data science, I felt completely lost and overwhelmed. But Ruby was there every step of the way, guiding me with immense patience and clarity. Her teaching style, which connects every concept to real-life examples, made learning effortless and unforgettable. Under her mentorship, I’ve gained not only knowledge but also the confidence to explore and excel in this field

Ruby is an invaluable member of our team, and honestly, without her, our work would be incomplete. She resolves every little and big error with ease. Not only does she teach, but she also explains concepts clearly, making learning effortless. Her real-life knowledge is truly unique and highly useful for our team. Projects that would typically take longer are completed swiftly under her guidance, making her an indispensable asset to our team.
Contact
Feel free to connect with me anytime!
Done!
Thanks for your message. I'll get back as soon as possible.Blog Posts